Severn Trent and the fear of self hosting
Jul. 3, 2023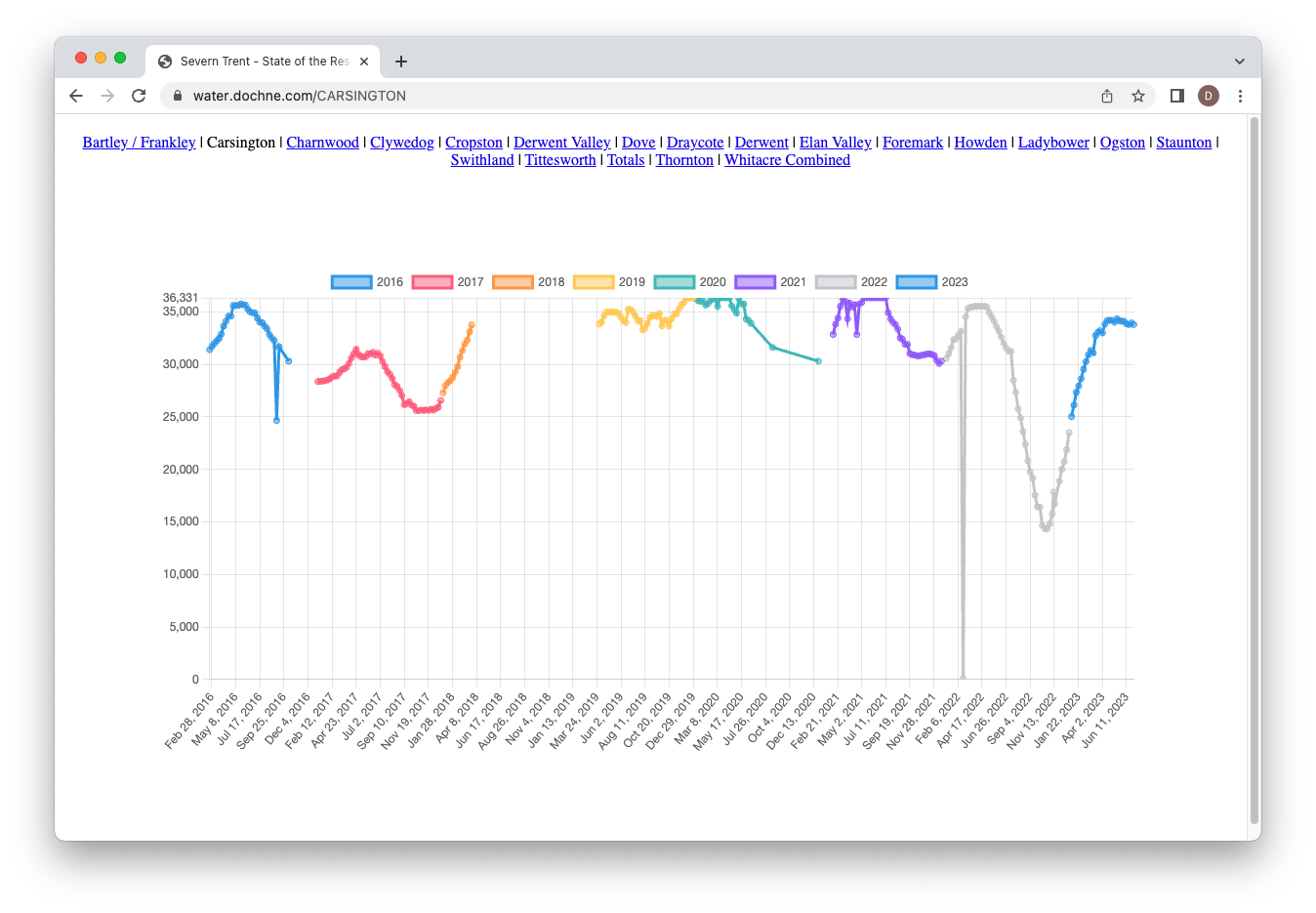
As time goes on, the idea of running servers on my own time becomes more and more frustating. I’ve spent enough time writing cattle systems that using pets for my own needs feels very unsatisfying.
As such, for my projects that are publically facing - I try pretty hard to avoid having a real backend server - if I can get away with just using a clients server, then joy is me.
I had some issues with this recently when I decided to create an application that graphed out the water levels in the reservoirs in my vicinity. The information is freely available online (although not in a parsable format) so the problem was really two fold:
- download this data
- displaying graphs/stats from this data
The first is easy enough (playwright/puppeteer) - the big question here is “what is the laziest way I can optimally download the data and push it to the frontend”
The naive solution is “download the data, then update your stash of data into some kind of JSON splat that can be AJAX’d”
The amazingly hacky solution is what I actually went with - with the advent of wasm, we can now use sqlite in the browser which allows for some amazingly hacky shenanigans in this space. As such, this works by:
- downloading the data to an sqlite database
- having the frontend download the entire database via AJAX then manually query the database on the frontend
Honestly, I’m amazed this works but it gives such flexibility to hacky projects like this - there’s a whole layer of “create an intermediatry data layer” that this eliminates.
You can see the project on GitHub here and the website for it here